作为在特斯拉和三星轮值过的六西格玛黑带,我见过太多技术团队把过程控制当成"例行公事"——数据照收,图表照画,报告照交,但问题照旧。今天我们就来解剖一个银行区块链节点的真实案例,看看如何让SPC控制图从"纸面稳定"变成真正的问题预警系统。
案例背景:银行区块链节点的"间歇性抽风"
某大型银行数字金融部的张工程师最近很头疼。他们的区块链节点响应时间(Response Time)就像个叛逆期的青少年——大部分时间表现良好,但时不时就"抽风"一下,导致交易延迟甚至超时失败。更糟的是,这些波动似乎毫无规律,运维团队疲于奔命却收效甚微。
"我们明明做了SPC监控啊!"张工向我展示他们的Xbar-R控制图,"你看,CPK值1.2,过程能力达标,但为什么生产环境还是频繁报错?"
我扫了一眼他们的控制图设置,立刻发现了三个致命伤——也是大多数技术团队在过程监控中常踩的坑。
问题一:采样间隔掩盖了真实波动模式
现象:他们的子组设计是每小时取5次响应时间,计算平均值和极差。图表显示"一切正常"。
诊断:区块链节点的性能波动往往发生在秒级或毫秒级。每小时采样的方式就像用渔网捞金鱼——网眼太大,关键信息全漏掉了。
真实案例:我们曾辅导某证券公司的交易系统优化,发现类似的采样问题。他们将每5分钟的成交延迟数据平均后输入SPC,结果完全错过了每秒级别的微突发(Microburst)现象,导致高频交易时滑点严重。
解决方案:
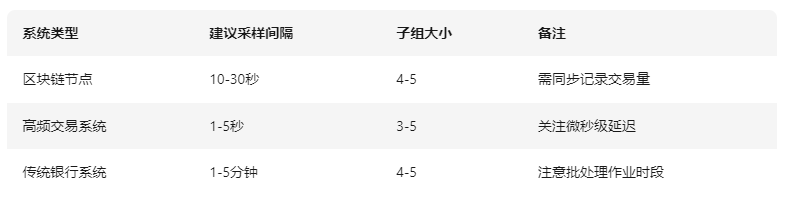
1. 缩短采样间隔:对于区块链这类实时系统,建议初始监控采用秒级或分钟级采样(如每10秒采1次,每5分钟形成一个子组)
2. 动态调整频率:根据初期数据表现,逐步优化采样策略。特斯拉的Autopilot数据采集就采用这种自适应方法
3. 记录上下文信息:每个数据点必须附带当时的网络状态、交易量、节点负载等元数据
表:不同系统推荐的初始采样频率
问题二:忽视判异规则导致早期预警失效
现象:团队只关注"点是否超出控制限",忽略了其他判异规则。
诊断:这就像只关心病人是否昏迷,却忽视所有前期症状。区块链系统的异常往往表现为趋势性变化而非突然崩盘。
真实案例:在三星半导体,我们发现某芯片测试良率看似"稳定",实则呈现连续14点交替上升下降的模式(判异规则4)。深入分析发现是测试设备的温度控制系统存在周期性波动,调整后良率提升3.2%。
解决方案:
1. 实施完整的八项判异规则:
- 规则1:1点超出3σ控制限
- 规则2:连续9点在中心线同一侧
- 规则3:连续6点递增或递减
- ...(完整八项规则见文末获取方式)
2. 建立规则-原因对照表:
规则3(连续6点上升)-->原因A[资源泄漏]
规则4(连续14点交替)-->原因B[周期性干扰]
规则7(15点集中在1σ内)-->原因C[测量系统失效]
```
3. 自动化报警:用Prometheus+Grafana等工具实现规则自动触发告警,避免人工遗漏
问题三:响应机制缺失让监控形同虚设
现象:即使控制图报警,团队也只是记录问题,很少立即采取行动。
诊断:没有闭环的监控就像没有刹车的汽车——能看到危险但无法停止。
真实案例:亚马逊AWS团队曾分享一个S3故障案例。监控系统提前2小时发出趋势性警告(连续8点上升),但因缺乏明确的响应流程,最终导致大规模服务中断。
解决方案:
1. 建立分级响应机制:
- 黄色预警(如规则4触发):自动发起诊断脚本,通知值班工程师
- 红色警报(如规则1触发):自动启动故障转移,召集应急小组
2. 实施Andon系统:借鉴丰田生产方式的"拉绳"机制,任何成员发现问题均可发起应急响应
3. 定期复盘报警:每周分析预警事件,更新应对预案。谷歌SRE团队将此作为黄金实践
实施效果:从混乱到可控的转变
经过三个月改进,该银行区块链节点实现了:
- 响应时间波动降低62%
- 异常事件平均修复时间(MTTR)从47分钟缩短至9分钟
- 相关故障工单减少78%
"**的收获不是图表变好看了,"张工在复盘时说,"而是我们终于能看懂系统在'说什么',能在用户投诉前解决问题。"
你的技术团队是否也在做"无效监控"?
问问自己这几个问题:
1. 我们的采样频率是否捕捉到了真实的波动模式?
2. 是否应用了完整的判异规则而不仅仅是"点出界"?
3. 报警后的响应流程是否明确且可执行?
4. 是否有定期评审机制持续优化监控策略?
想获取《技术系统SPC监控完整工具包》?包括:
- 八项判异规则技术版详解(含IT系统典型症状对照)
- 采样频率计算器(Excel模板)
- 区块链/分布式系统监控Checklist
- 2个金融级真实案例详解
复杂系统需要定制化监控方案?张驰咨询团队结合亚马逊、特斯拉等顶尖科技公司实践,为您打造真正有效的技术监控体系。从数据采集到智能预警,从根因分析到自动修复,让您的系统稳定性迈上新台阶。